Last Updated on 2024-07-06 by BallPen
표준 오차의 도입 배경과 개념이 궁금합니다. 또한 표준 오차 계산은 어떻게 할까요?
표준 오차 개념을 이해하는 것은 측정값의 정확도를 올바르게 표기하는데 있어 아주 중요합니다.
계산은 비록 어렵지 않으나 그 개념을 이해하기는 쉽지 않아요. 그럼 이제부터 표준 오차의 도입 배경과 개념, 그리고 계산 방법을 함께 알아봐요.
목차는 다음과 같습니다.
Contents
1. 정확도와 정밀도 복습
이전 포스트에서 측정 결과의 정확도와 정밀도에 대한 개념, 계산, 표기 방법에 대해 설명드린 바 있습니다. 간단히 복습해봐요.
각각의 구체적인 계산법은 이전 포스트를 참고하세요.
1-1. 정확도
정확도는 참값에서 측정값이 얼마나 떨어져 있는가를 나타내는 척도이며, 표기 방법은 아래 네가지 방법 중 하나를 적용하면 됩니다.
– 평균값과 참값의 백분율
측정값들의 평균값을 \mu, 참값을 X라 할때 정확도는 다음과 같습니다.
\tag{1} 정확도(\%) = {{\mu}\over{X}} \times 100
– 절대오차
측정값(또는 측정값들의 평균값)을 x, 참값을 X라 할 때 절대오차 \epsilon은 다음과 같습니다.
\tag{2} \epsilon = x-X
– 상대오차
상대오차 또는 백분율오차는 다음과 같습니다.
\tag{3} 상대오차(\%) = {{|\epsilon|}\over{X}} \times 100
– 표준오차 SEM
바로 이 글에서 다룰 내용입니다.
1-2 정밀도
정밀도는 측정값들의 퍼짐 정도를 나타내며, 표기 방법은 아래 네가지 방법 중 하나를 적용하면 됩니다.
– 상대표준편차
측정값의 표준편차를 \sigma, 평균값을 \mu라 했을 때 상대표준편차 \% \mathrm{RSD}는 다음과 같습니다.
\tag{4} \% \mathrm{RSD} = {{\sigma}\over{\mu}} \times 100
– 측정값의 범위
측정값의 최대값인 x(max)과 최소값인 x(min)으로 range를 구합니다.
\tag{5} Range = x(\mathrm{max})-x(\mathrm{min})
– 평균편차
측정값을 x, 측정값의 평균을 \mu라 했을 때, 평균편차 \bar d는 아래 식으로 계산합니다.
\tag{6} \bar d = {{\Sigma |x-\mu|}\over{n}}
– 표준편차
모집단 표준편차 \sigma 또는 표본 표준편차 s는 아래 식으로 계산합니다.
\begin{align}
\tag{7}
\sigma = \sqrt{{\Sigma (x-\mu)^2}\over{n}}= \sqrt{Var[x]} ~ (모집단 표준편차) \\
\end{align}\tag{8} s = \sqrt{{\Sigma (x-\mu)^2}\over{n-1}} ~ (표본 표준편차)
(7)식에서 Var[x]는 모집단의 분산을 뜻합니다.
2. 표준 오차 도입 배경
앞에서 이미 이해하셨겠지만 정확도는 오차로 평가되고, 정밀도는 편차로 평가됩니다.
그런데 여기서 한가지 궁금한 사항이 있어요. 정확도에서 오차를 구하기 위해서는 참값이 필요한데 현실적으로 참값을 모르는 경우가 많아요.
예를 들어 어느 물체가 있다고 하겠습니다. 그 물체의 질량을 알고 싶어 저울을 이용해 측정했다고 생각해봐요. 아래와 같이 총 6번 측정했어요.
12.0, 12.3, 11.8, 11.9, 12.4, 12.1 kg
위 측정 결과로부터 정밀도와 관련된 편차는 계산할 수 있습니다. 물론 평균값 \mu도 계산할 수 있어요.
그런데 정확도와 관련된 오차는 어떻게 구할 수 있을까요? (1), (2), (3)식에서와 같이 정확도를 구하기 위해서는 참값을 알아야 하는데 참값을 알지 못하는 거죠.
이러한 문제 상황에서 출발한 것이 표준오차입니다.
즉, 표준오차 개념을 이해하면 참값, 그리고 참값이 존재할 범위와 확률을 구할 수 있어요.
3. 표준 오차 개념
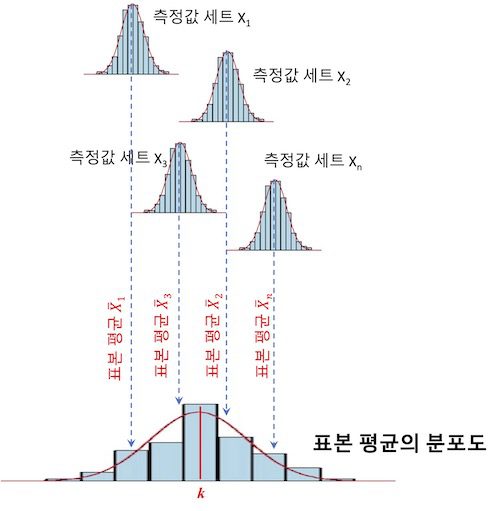
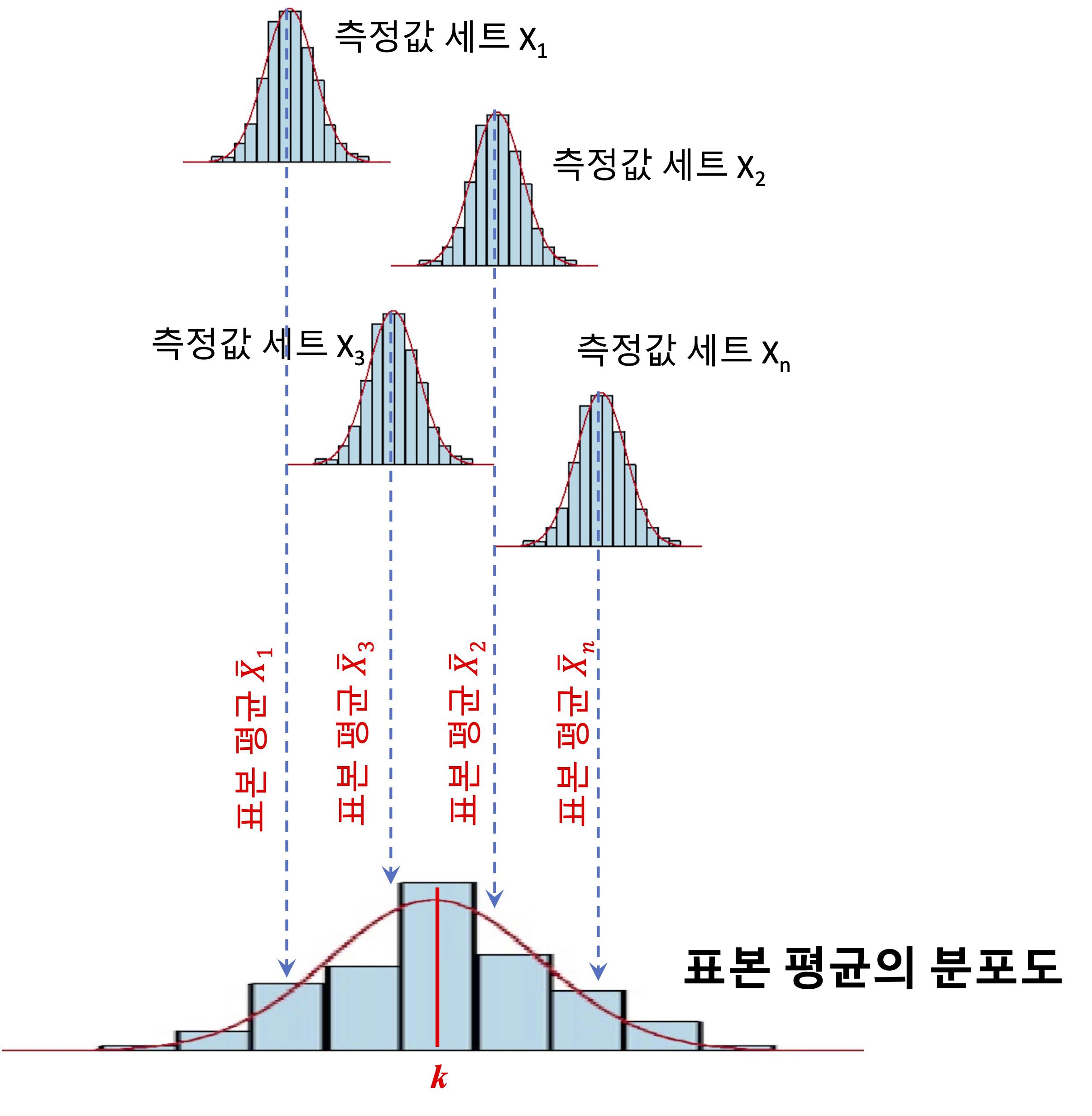
어느 물체의 질량을 측정하기 위해 저울을 이용합니다. 이때 A라는 사람이 자신이 갖고 있는 저울을 이용해 물체의 질량값을 6번 측정했고, 그 측정한 값들의 세트인 X_1이 아래에 주어져 있습니다.
X_1 = {12.0, 12.3, 11.8, 11.9, 12.4, 12.1 kg}
이 값의 평균은 12.1 kg 인데요. 이 값이 참값일까요? 아닙니다.
12.1 kg이라는 값에는 계통오차가 포함되어 있기 때문에 엄밀하게 참값이라고 할 수 없습니다. 그렇다면 계통오차를 제거하여 참값을 도출하는 방법은 무엇일까요? 바로 아래에서 설명할 표본 평균의 평균이라는 개념을 이용하면 계통오차를 제거할 수 있어요.
우선 단계적으로 표본 평균의 평균을 구하는 방법을 설명드리고 표준오차를 구체적으로 설명드립니다.
3-1. 표본 평균의 평균
- (1단계) n명의 사람들이 자신의 저울을 이용해 각각 물체의 질량을 n번 측정한다고 생각하세요. 그러면 n개의 측정값 세트인 표본 X_1, X_2, X_3, \cdots, X_n이 얻어지겠죠. 이때 주의할 것은 n명의 사람들은 자신의 저울을 갖고 있는 것이고, 동일한 물체를 돌려가며 각각 n회 측정했다고 생각해야 합니다. 절대로 동일한 저울 하나를 두고 사람들이 줄서서 각각 n회 측정한 개념이 아니에요. 그래야만 논리적으로 각각이 갖는 계통오차가 서로 상쇄됩니다.
- (2단계) 각 측정값 세트, 즉 표본의 평균을 내세요. 그러면 \bar{X}_1, \bar{X}_2, \bar{X}_3, \cdots, \bar{X}_n들이 구해질 것입니다. 이것이 표본 평균입니다.
- (3단계) 2단계에서 구한 표본 평균들의 평균을 구하세요. 그 값을 k라고 할께요. 이 값이 표본 평균의 평균값입니다.
(3단계)에서 구한 표본 평균의 평균 k는 n개의 표본 평균으로부터 구한 평균값이기 때문에 각 표본이 갖는 계통오차들이 서로 상쇄되어 제거된 것으로 볼 수 있습니다.
즉 어느 표본에서 양의 계통오차가 발생했다면 다른 표본에서는 같은 크기의 음의 계통오차가 발생되어 서로 상쇄되어 제거되고 결국 참값만 남게 되는 원리이죠. 물론 많은 표본을 운영할 수록 참값에 가까워집니다.
그러므로 표본 평균의 평균 k를 개념적으로 참값으로 간주합니다.
3-2. 표준 오차 정의
표준 오차 SEM은 표본 평균의 표준편차로 정의됩니다. 즉 참값 k로부터 표본 평균들이 얼마나 흩어져 있는가를 평가하는 척도인 거죠.
그러므로 (7)식의 모집단 표준편차 공식을 그대로 사용하는데요. 다만 변수 x 대신에 표본 평균 \bar{X}_1, \bar{X}_2, \bar{X}_3, \cdots, \bar{X}_n가 적용되고, 평균값 \mu 대신에 표본 평균의 평균 k가 적용됩니다.
이를 식으로 표현하면 다음과 같습니다.
\begin{align}
\tag{9} SEM &= \sqrt{{\Sigma (\bar{X} - k)^2}\over{n}} \\[10pt]
&=\sqrt{Var{\bar{\big[ X \big]}}}
\end{align}(9)식에서 Var\big[ \bar{X} \big]를 표본 평균의 분산이라고 합니다.
4. 표준 오차 공식과 모집단 표준 편차 추청
(9)식을 이용하면 표준 오차 SEM을 구할 수 있습니다. 물론 수많은 반복 실험을 통해 표본 평균 \bar{X}를 구한 후 참값 k를 구해야 겠죠.
그러나 현실에서는 그렇게 수많은 표본들을 구하는 것이 쉽지 않아요.
예를 들어 어떤 실험을 통해 단지 하나의 실험값 세트만 있을 때에는 표준 오차를 어떻게 구할 수 있을까요?
이럴 때는 바로 측정값으로부터 모집단의 표준 오차 \sigma를 추정하는 방법을 사용합니다. 구체적인 내용은 아래에 계속 설명드립니다.
4-1. 표준 오차 공식의 일반화
일단 통계학적인 수식 처리과정을 거쳐 보겠습니다. 흐름은 위에서 개념 설명할 때와 같습니다.
n명의 사람들이 각각 n회씩 측정합니다. 그러면 i번째 측정세트는 표본 X_i이고 이러한 표본들이 n개가 있는 것이죠.
한 표본에서의 평균인 표본 평균 \bar{X}는 아래와 같이 구해집니다.
\tag{10} \bar{X}={{1} \over {n}} \sum_{i=1}^{n} X_i
표준 오차의 정의 식인 (9)식에서 근호안에 있는 분산을 우선 표현하면 다음과 같습니다.
\begin{align}
\tag{11} Var \big[ \bar{X} \big] &= Var \Big[ {{1}\over{n}} \sum_{i=1}^n X_i \Big]\\[10pt]
&= Var \Big[ {{1}\over{n}} (X_1 + \ldots + X_n) \Big] \\[10pt]
&= {{1}\over{n^2}} Var[X_1 + \ldots + X_n] \\[10pt]
&= {{1}\over{n^2}} \times \big( n \times Var[X] \big) \\[10pt]
&= {{1}\over{n}} Var[X]
\end{align}(11)식 전개 과정에서 다음의 성질이 이용되었습니다.
\tag{12} Var[aX+b] = a^2 Var[X]
\begin{align}
\tag{13} Var[X_1 + \ldots + X_n ] &= Var[X_1] + \ldots + Var[X_n] \\[10pt]
&= n \times Var[X]
\end{align}이때 (13)식에서 Var[X]는 모집단의 분산을 뜻합니다. 이것은 n이 크다면 모집단에서 추출되는 각 표본의 분산은 모집단의 분산과 같다는 통계학적 의미가 반영된 것입니다.
(11)식을 이용하여 (9)식의 표준 오차 SEM을 정리하면 아래와 같습니다.
\begin{align*}
SEM &= \sqrt{Var[\bar{X}]} = \sqrt{{{1}\over{n}} Var[{X}]} \\[10pt]
&= \sqrt{{\Sigma({x} - \mu)^2}\over{n\times n}} \\[10pt]
&= {{\sigma}\over{\sqrt{n}}}
\end{align*}결국 표준 오차 SEM은 모집단의 표준편차 \sigma를 \sqrt{n}으로 나누면 간단히 구해집니다.
그런데 문제는 모집단의 표준편차 \sigma를 어떻게 구하느냐인데요.
보통은 모집단의 표준편차를 구하지 못하니 측정값들의 표준편차 s를 구하고 이것을 모집단의 표준편차 \sigma의 추정치로 활용하게 됩니다.
결국 실험세트가 단지 하나인 경우에 SEM은 아래와 같이 구합니다.
\tag{14} SEM = {{s}\over{\sqrt{n}}}
4-2. 표준 오차 SEM을 이용한 측정값의 표기
(9)식 또는 (14)식으로 구한 표준오차 SEM을 이용해 측정값들의 대표값을 표기하는데요.
바로 아래 (15)식과 같이 “평균값\pm(Z-score \times SEM)”의 형식을 사용합니다.
\tag{15} \bar{X} \pm Z{{s}\over{\sqrt{n}}}
이 식에서 Z는 90% 신뢰수준의 경우 1.65, 95% 신뢰수준의 경우 1.96, 99% 신뢰수준의 경우 2.58을 적용합니다. 연구에서는 보통 95% 신뢰수준을 적용합니다.
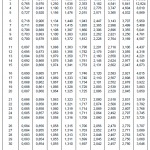
정규분포표의 Z값을 적용하는 것은 실험세트의 측정값이 100개 이상인 경우에 보통 적용합니다. 만일 측정값이 100개 미만인 경우에는 (15)식에서 Z대신에 t분포값이 들어갑니다.
예를 들어 95% 신뢰수준에서 측정값이 5개 뿐인 경우에는 아래 (16)식과 같이 표기합니다. t분포표 보는 방법은 아래 예제를 참고하시기 바랍니다.
\tag{16} \bar{X} \pm 2.776 {{s}\over{\sqrt{n}}}
5. 계산 방법 예제
6. 표준 오차 개념, 공식, 계산 방법의 정리
- 표준 오차란 표본 평균의 표준편차이다.
- 오차 용어를 사용하는 이유는 표준 오차 공식에서, 표본 평균의 평균값 k를 참값으로 간주하고 표본 평균과의 차이인 오차 개념이 적용되기 때문이다.
- 표준오차는 측정값의 표준편차를 구한 후 그 값을 \sqrt{n}으로 나누면 간단히 구할 수 있다.
- 반복실험에 의해 측정값이 100회 이상인 경우에는 정규분포의 신뢰수준에 따른 측정값 표기방식을 따르고 100회 미만인 경우에는 t-분포표에 따른 표기방식을 따른다.
- 만일 측정값이 단지 5개 미만이라면 무리해서 표준 오차를 구하는 것보다는 평균치와 표준편차를 그대로 보여주는 것이 좋다.






nice
안녕하세요. 포스팅 자료 감사합니다!
표준오차를 공부하던중 의문점이 있어 댓글 남깁니다.
4-1 표준오차 구하는 부분에서 “n개의 표본을 n번추출한다”고 하시고 공식을 설명하셨는데 표본의 개수와 표본을 추출하는행위의 횟수 자체는 서로 다른 개념이기때문에 구분을 해야하지 않을까 싶은데요.
“n개의 표본을 m번 추출한다” 라고 명확하게 구분지어 논리를 이어나갈경우 (11)번 식에서
VAR[X(상단바)] = VAR[X]/m 이 되어
여기서 말하는 m이란 추출횟수이지 표본개수 n을 말하는게 아닌거 같습니다.
예를 들어 모집단 60000개 중에서 표본300개를 추출하는 작업을 10번 반복하여 조사했다고 할때 n=300 m=10 이 되어, 표준오차를 구할때 표본개수 n=300이 아닌 10으로 나누어주어야하는거 아닌가 하는 의문점입니다.
따라서 단 한번의 추출행위만으로는 표준오차를 구할 수 없고 최소 두번이상의 표본추출 행위를 통해 표본들간에 분산을 구했을때 그때의 편차를 표준오차라고 볼 수 있지 않을까 하는 궁금증입니다.
이부분에서 다양한 학습자료들을 통해 이해해보려고 해도 거의 모든곳에서 n과 m의 개념적 구분없이 n으로 합쳐 설명하기 때문에 명확한 답을 얻기 힘든데, 도수분포표 그림을 첨부하여 표본 평균의 평균이라는 개념을 소개하시고 표준오차의 개념에 대해 이해하기 쉽게 설명하시는 분이라는 생각이들어 질문을 남기게 되었습니다.
귀찮은 질문일 수 있는데 죄송하고 감사합니다ㅎ
안녕하세요? 제 블로그를 방문해주셔서 감사합니다.
우선 말씀하신 내용부터 답변드립니다.
1. ‘n개의 표본을 n번 추출한다’고 일부러 쓴 것입니다. 그래야만 (11)식에서 n이 약분되어 1/n만 남게 되기 때문이에요. 만일 말씀하신대로 ‘n개의 표본을 m번 추출한다’고 하면 (11)식에서 m/n^2이 나오게 될거에요. 여기서 n은 (10)식에서 들어간 것이고, m은 (11)식의 괄호안에서 들어간거에요. 이때 n과 m을 모두 알고 있다면 전혀 문제될 게 없습니다.
2. 하지만 문제는 한 사람만이 추출행위를 한 경우인데요(본문에 링크된 예제 참고). 본문에서 말씀드린것처럼 현실적으로 이러한 경우가 더 많아요. 예를 들어 누군가가 질량값 (12.0, 12.3, 11.8, 11.9, 12.4, 12.1)의 값을 얻었을 때 질량의 참값을 이 값들의 평균인 12.1이라고 합니다. 이 논리는 어떻게 나온거냐면 위에서 나열한 숫자들을 표본 평균으로 간주하는거에요. 그러면 표본 평균의 평균을 참값으로 볼 수 있으므로 12.1이 참값이 되는 논리입니다. 그러면 표준오차도 계산해봐요. 만일 ‘n개의 표본을 n번 추출한다’고 생각하면 (14)식처럼 표준오차가 표현되어 n에 6을 대입하면 쉽게 구할 수 있어요. 하지만 ‘n개의 표본을 m번 추출한다’고 하면 (11)식에서 n과 m이 모두 들어가 있으므로 (14)식의 표준 오차 공식에도 n과 m이 모두 남아있게 되겠죠. 그러면 m은 6을 대입하면 되는데, n에는 얼마를 넣어야 하는냐는 고민이 생깁니다. 어차피 하나의 실험세트에서 논리적 추정을 통해 표준오차를 구하는데 n 때문에 고민하면 안되니 차라리 n개의 표본을 n번 추출한 것으로 가정해서 식을 단순하게 만든 것으로 보면 좋겠습니다.
어떻게 답변이 잘 되었는지 모르겠습니다. 저도 통계 전문가는 아니라 글을 쓰고 답변을 다는데 한계가 있습니다. 그래도 방문자님께서 질문을 해주셔서 다시 한번 글을 전체적으로 손질하는 계기가 되었습니다.
다시 한번 더 방문해주셔서 감사드립니다. 오랜만에 즐거운 시간을 보낼 수 있었어요.